Scott A Hale探讨了语言对在网上搜寻和传递讯息的影响。

言论自由大讨论的第一原则阐释了“无分国界,寻求、接受和传递各种讯息和思想”的权利。不过,语言是最明显却也最少人研究的国界。言论自由大讨论意识到了这一点,所以致力于把内容翻译成十三种语言这样浩大的工程。
语言到底会如何影响网络上的信息搜索和传播呢?现存的研究并未深究这个问题,而这也不是本文可以全面探讨的。不过,搜索引擎让我们可以一瞥不同语言间内容上的差异性。在搜索图片时,搜索引擎会试着把关键字和图片周边的文字、图片名和图片的链接文字配对。我们也许会认为,既然图片名往往独立于其描述文字,搜寻结果在不同语言间会大致相同。然而,图片的上传和注解取决于特定的社会语言背景。尽管谷歌不是所有市场中的主要搜索引擎提供者(雅虎日本、 Yandex和百度分别在日本、俄罗斯和中国各自占有更多市场),但它在全球仍有领导地位,收录了大量的内容;在跨语言搜寻时,我们可自然推论,谷歌即使不使用完全相同的算法,也会用近似的算进行搜索容。因此,搜索同样地点,却在不同语言间得到不同结果,着实让人惊讶。
图一和二是用英文和中文谷歌图片搜索“天安门广场”的结果。所有的搜索都使用google.com,在英国的同一台电脑上先后执行搜索。然而,搜寻结果却大庭相 径:这些差异有些并无大碍,但有的差异却让人担忧。例如搜索“天安门广场”的结果,显示出对1989年抗争事件的图片纪录,在中文和英文目录的数量有很大的落差。

图一:用英文在谷歌图片上搜索天安门广场的结果
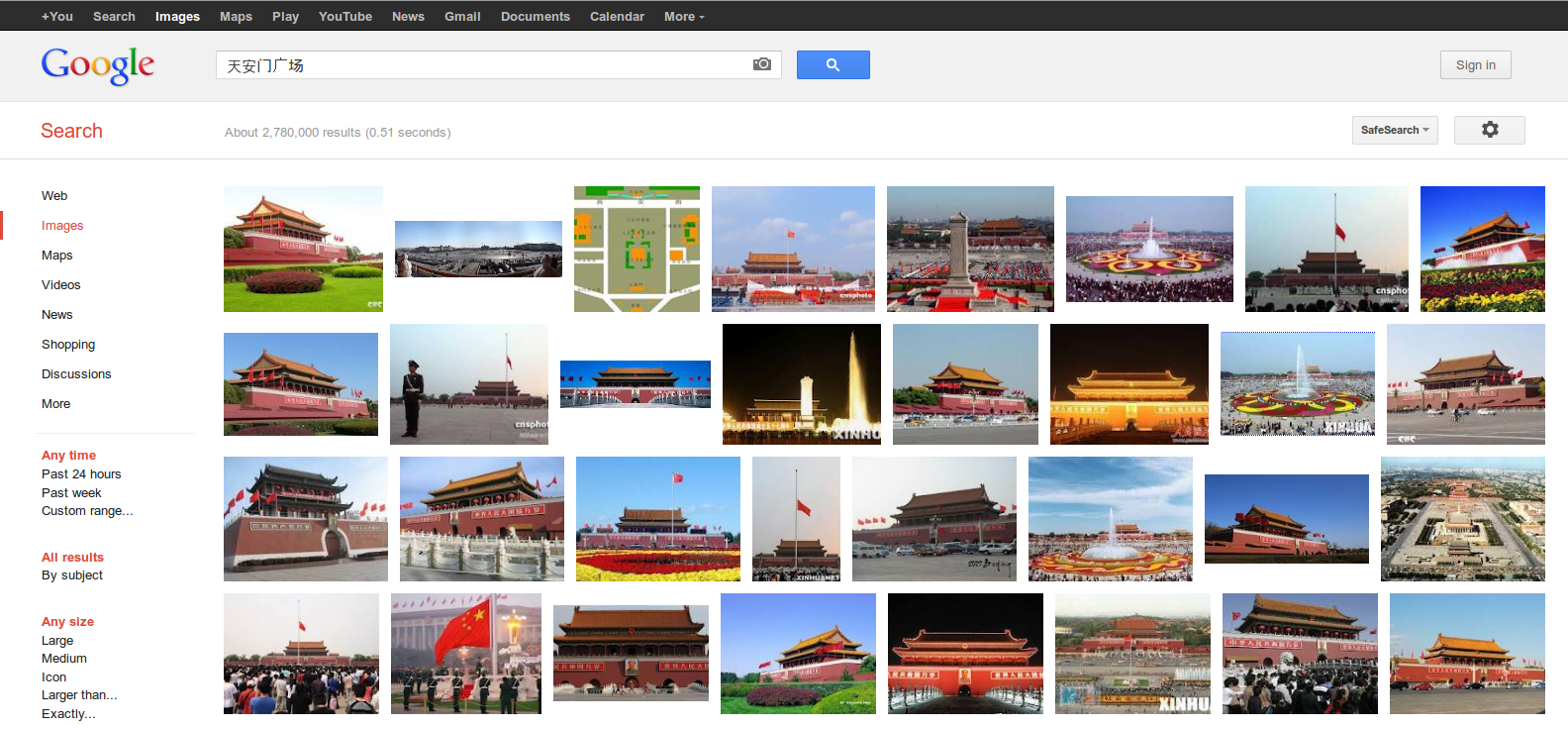
图二:用中文在谷歌图片上搜索天安门广场的结果
其他更有系统的研究,针对网路维基百科在不同语言版本间的不同,进行了调查。 这些研究结果也显示“不同语言版本间重叠的内容少得惊人”(Hecht & Gergle, 2010)。最有趣的是,即使目前最庞大的版本,即英文版维基百科,平均来说也只包含了其他任何一版本讨论概念的60%(重叠率最高的是英文和希伯来文,比例达75%)。事实上,和第二大版本德文版维基百科相比,英文版只涵盖了德文版大约一半的概念;而德文版只涵盖了16%的英文文章。当然,即使“两种语言版本涵盖相同概念(非常清晰阐释), 他们对概念的描述仍有可能有所不同”,Hecht & Gergle (2010)在他们的研究中对这个概念有更深入的分析。另外他们也提到如Omnipedia等新工具,可以让使用者探索不同语言版本间的差异。
这些现象并不都是负面的。事实上,有几个平台已经完全渗透全球(Facebook, Twitter, YouTube, 和Wikipedia只是其中几个例子)。这些平台上的社群沟通虽然离不了单一语言,但他们使资讯得以以前所未见的高速跨越国界传递。我的研究包含2010海地地震后讨论此事的博客(图三)和2011日本海啸地震后,维基百科和Twitter上的连结分享;再加上Irene Eleta对Twitter的研究,都显示了资讯散布横跨各语言的例子,也展现出有多种语言能力的使用者群有“桥结点”的功能,让资讯可以在不同语言团体间散布。
资讯在不同语言间扩散也有其科技和社会的面向。机器翻译并非完美无误,但它仍成功使其他语言内容有高参与度;进一步的研究和训练资料也会持续增强机器翻译系统。另外,有的研究—包含我的研究—针对设计的角色,分析其如何影响使用者跨语言探索和传布赀讯。这些研究都有其必要性。而社交媒体公司在建立新平台时,也应该利用这些研究并参考更广泛的社会科学研究的成果。当然,崭新的工具也会善用电脑和使用者的技术,在突破语言界限上有所收获。 Doulingo 和 Monotrans2 正是这种例子。他们让只会一种语言的使用者可以翻译内容。就Dounlingo来说,使用者还可以同时学习新语言。不过,人类翻译的确有不可取代的地位;重要事件在不同语言中的讯息也要靠新的媒体组织辨其真假。
Scott A Hale是the Oxford Internet Institute的研究助理和博士候选人。





















reply report Report comment
Dear Mr. Hale. My name is Victor. T.W. Gustavsson and I go the University of the Hague studying the meaning and use of the English language. After reading your article, I was left with some unanswered question marks. Do computers really translate information in a way that alters the content and meaning of a text from one language to another? And if so, should we leave these translations to computers, if it comes to the point where these faulty translation can cause harm and/or misunderstandings?
Your argument that different countries include different information about the same event is just logical, as different countries have dissimilar cultures and beliefs which will shape what information they focus on and the way they structure their information and websites. For example, Google searches in one language will not give you the same suggestions as if you would Google the same thing in a different language. So it rather comes down to internet censorship which plays a huge role when it comes to what information is allowed to be published on the internet, making these searches bias depending on what country you are searching from or in what language you make the search.
Furthermore, your images showing the different search results of China’s Google and the UK’s Google demonstrate the censorship of China compared to the UK’s freedom of speech. Your argument is based upon the supporting evidence that the search results are different, yet your example actually only proves the opposite as it demonstrates how much influence governments have on the internet. It is only logical that the search results in China will be different than in the UK due to their different cultures and standpoints regarding freedom of speech. If we look at the past, the UK has been much more open as a society and as a government compared to China, therefore, it would only be logical if this were to be represented on the internet.
You are simply stating the obvious. Instead of developing your own ideas or theories, you rephrase what has been addressed in the past by experts in the field. China’s government censors the internet, as the Tiananmen Square example shows; it has done so for years.You mention that “search engines provide one window into the differences in content between languages,” yet I have conducted my own research and have found that searching ‘911’ or ‘Taliban’ on the Arabic Google and the UK Google have similar findings, unlike the Tiananmen Square example. This search was carried out from a computer in The Netherlands, with only a few minutes time difference between each search. I believe your argument is more supporting of government censorship on the internet rather than false translation due to internet translations.
In countries where no government censorship is present, such as Afghanistan or the United Kingdom, the search results are similar because it represents what people post or search on the internet. This suggests that your argument that “search engines try to match query words to the text that appears near images in web pages” is invalid, as it is only due to government censorship.
It therefore should also not be striking that there are differences in results between different countries such as China and the UK, as you suggested. Yet Google, who are determined to encrypt their algorithms due to the recent NSA affair, will prevent China from censoring Google in the future as easily (Washington Post, “Google is encrypting search globally. That’s bad for for the NSA and China’s censor’s”). I am convinced that if we were to compare the results of a Google Images search of “Tiananmen Square” between the Chinese Google and the United Kingdom Google in five year’s time, there would be little difference, as technology is ever improving and censorship is becoming more evident. Therefore I am not sure what your argument states, as your resource contradicts your sophism, actually illustrating that the internet is not free, and that Google’s algorithms can easily be hacked by governments.
You stated that translations on huge encyclopedias such as Wikipedia, are generated by sophisticated computer algorithms which are not nearly as accurate as real-life translators. However, according to Bill Bryson’s Mother Tongue, different languages may have as many as thousands of different words for what we have in English only a few for, “the Arabs are said (a little unbelievably, perhaps) to have 6,000 words for camels and camel equipment”. This could possibly confuse these computer softwares to misinterpret some words which could eventually lead to “overlap” as you said. This raises a question of, just as it is people’s job to translate in real life, should there be designated translators whose job it is to accurately translate content from English to or from any other language. Before the internet existed, works were already being translated and these seem to be much more accurate than many of the articles and pieces on the internet. You can argue that these have been checked over and over again by publishers, but, do computers not double check?
You mentioned explicitly that there are large overlaps between English and other languages with “overlap is between English and Hebrew is 75%”, yet a few sentences later you stated that “several platforms have achieved truly global penetration (Facebook, Twitter, YouTube, and Wikipedia)”. Nonetheless, one big reason why German contains about 16% of the articles in English” is because Wikipedia has a policy where users request pages to be translated. Because English is one of the primary languages in our modern world and most internet websites and activity is done in English, it is only logical to give the English language priority when it comes to translation. Therefore, only the most important (which the user thus decides) gets translated to a foreign language. Country specific topics such as the German National anthem should undoubtedly be different than when it is translated in English.
I do agree howbeit, that machine translations aren’t flawless and that in time these will get more and more sophisticated. But do we really want computers to take over almost everything in the digital world, even the one thing we have developed over the course of thousands of years as a human race, language?
reply report Report comment
Dear Victor,
Thank you for reading and responding to my article. I’m afraid, however, that there have been some misunderstandings. I respond to some questions and point out some of these misunderstandings below.
> Do computers really translate information in a way that alters the content and meaning…
I only mention that machine translation has some errors, and do not discuss machine translation in depth in this piece. The focus of this article is on the content produced by humans in different languages (of which human translations are a small part). In the case of human produced content, yes, there are often differences in meaning and content across languages.
> Your argument that different countries …
This article only discusses languages and not countries. The example Google searches are both performed in the UK on the .com version of Google as stated in the article. Only the languages of the search queries were different. I admit, however, that the example queries could have been better chosen (and originally I had a gallery of many examples, but for technical limitations of this site it was not included. It is available on my own website: http://www.scotthale.net/blog/?p=275).
> “search engines provide one window into the differences in content between languages”
I stand by this, and note that similarity between two languages for one search doesn’t disprove that there are differences between some languages (and data shows most languages). It is also important to note that Google is constantly changing its search algorithms, and it is very possible that they are now using translations of search terms to produce more similar image results in different languages. I know that this was already being considered two years ago when I wrote this article, but I don’t know if it has been implemented.
> In countries where no government censorship is present….
Again, I’m concerned about language, not countries, and
> I am convinced that if we were to compare the results of a Google Images search of “Tiananmen Square” between the Chinese Google and the United Kingdom Google in five year’s time, there would be little difference
I’m not sure on this point. Note again that both of my searches were from the UK and performed on the .com version of Google. If the Chinese government remains successful in ensuring that most mentions of Tiananmen Square in Chinese occur around benign photos (e.g., through controlling the publishing of content in the country with the largest Chinese-speaking population in the world), then any language-independent image search algorithm will most likely find these benign photos and rank them more highly than ‘obscure’ photos that occur around the phrase “Tiananmen Square” in Chinese in a small amount of content.
> You stated that translations on huge encyclopedias such as Wikipedia, are generated by sophisticated computer algorithms which are not nearly as accurate as real-life translators.
I do not state this. In general, Wikipedia does not include raw/pure machine translation without a human in the loop. (https://meta.wikimedia.org/wiki/Machine_translation)
> You mentioned explicitly that there are large overlaps between English and other languages with “overlap is between English and Hebrew is 75%”, yet a few sentences later you stated that “several platforms have achieved truly global penetration (Facebook, Twitter, YouTube, and Wikipedia)”.
There is no contradiction between these two sentences. The first discusses content overlap between languages; the second discusses the geographic breadth of users of websites.
> I do agree howbeit, that machine translations aren’t flawless and that in time these will get more and more sophisticated. But do we really want computers to take over almost everything in the digital world, even the one thing we have developed over the course of thousands of years as a human race, language?
On this point we can agree :-). Humans play important roles in producing, seeking, and consuming content in different languages. My research argues that a better understanding these human roles (particularly those of bilinguals) is needed in order to better design platforms. I encourage you to take a look at my own website and get in contact with the contact form there if you want to discuss anything further. http://www.scotthale.net/
Best wishes,
Scott