Scott A Hale explores the effect of language in seeking and imparting information on the broader web.

The first draft principle of Free Speech Debate addresses the right to “seek, receive and impart information and ideas, regardless of frontiers”. One of the most obvious, but least studied frontiers online is language. FSD recognises this and has committed to an impressive program of translating content into thirteen languages.
What, however, is the effect of language in seeking and imparting information in the broader web? Existing research does not fundamentally address this question, and it is not a question that can be addressed fully within this post. Yet, search engines provide one window into the differences in content between languages. When searching for images, search engines try to match query words to the text that appears near images in webpages as well as to the filenames of the images and to the words in links to the images. On the one hand, we might expect image results to be broadly similar across languages as images can often be understood independent of descriptive text. Yet images are uploaded and annotated within specific cultural-linguistic settings. While Google is not the dominant search provider in all markets (Yahoo! Japan, Yandex and Baidu have more market share in Japan, Russia, and China respectively), it is still is the global search leader, indexes huge amounts of content, and presumably applies similar, if not the same, algorithms to searching content in different languages. This makes the differences in results between searches for different places very striking.
Figures 1 and 2 show results for Google Image searches for Tiananmen Square in English and Chinese. All search queries were conducted moments apart from the same computer in the UK using google.com; yet, the results are surprisingly different in sometimes innocuous and sometimes concerning ways. The results for Tiananmen Square, for instance, reveal a disparity in the number of images indexed in English versus in Chinese about the protests of 1989.

Figure 1: Google Image search results for Tiananmen Square in English
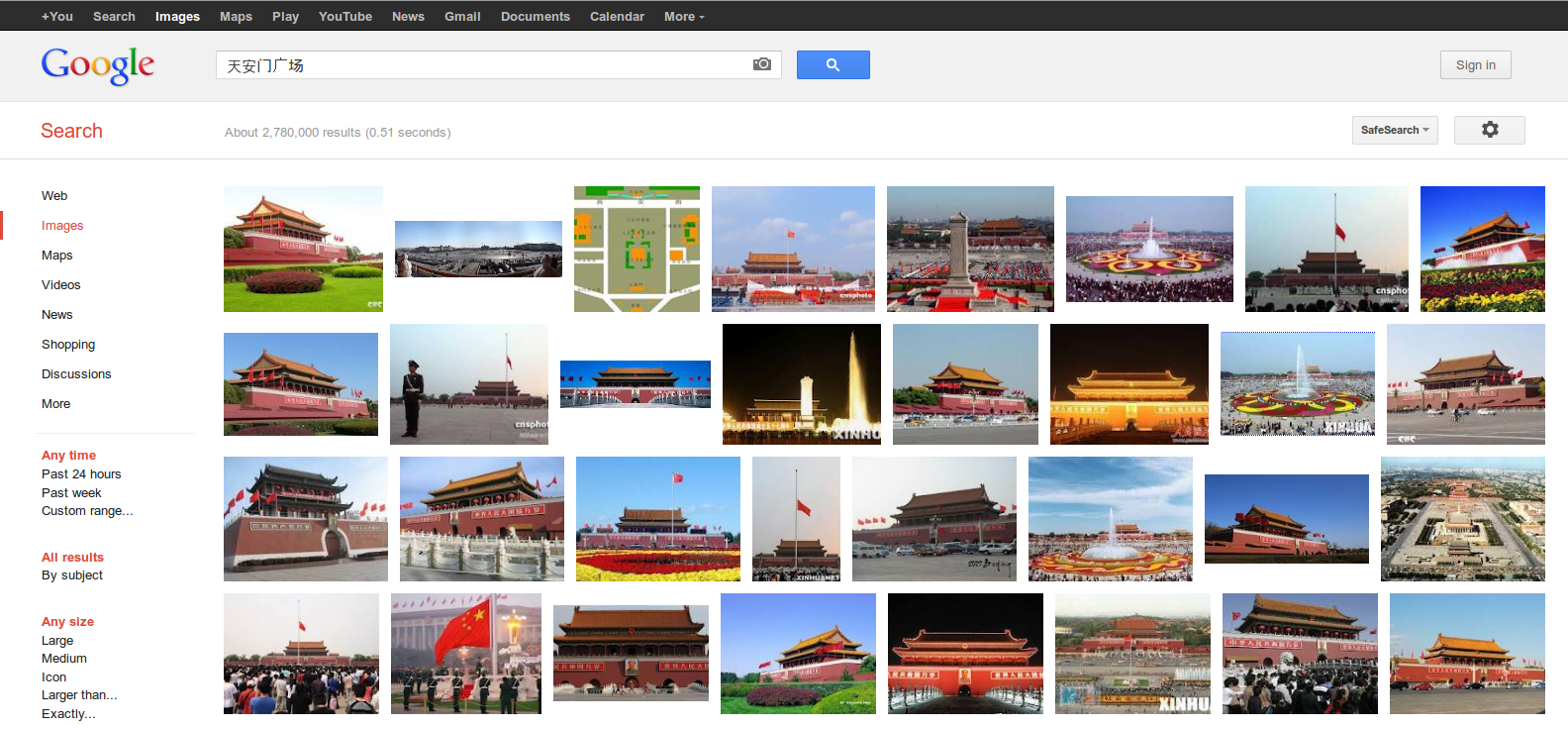
Figure 2: Google Image search results for Tiananmen Square in Chinese
More systematic study of the differences between language editions of the online encyclopedia Wikipedia also show “a surprisingly small amount of content overlap exists between language editions of Wikipedia” (Hecht & Gergle, 2010). Particularly interesting is that even the English edition, by far the largest edition of the encyclopedia, contains on average only 60% of the concepts discussed in any other Wikipedia edition in the study. (The highest overlap is between English and Hebrew at 75%.) In fact, English contains only about half of the concepts found in the second-largest edition, German, while German contains about 16% of the articles in English. Of course, even where “two language editions cover the same concept (with perfect clarity), they may describe that concept differently”, a point Hecht & Gergle (2010) analyse further in their paper and also address with new tools such as Omnipedia, which allows users to explore the differences between language editions.
This is not all doom and gloom, however. Several platforms have achieved truly global penetration (Facebook, Twitter, YouTube, and Wikipedia to name a few), and while communications on these platforms are primarily within language, these platforms also open the possibility of spreading information across frontiers at unprecedented speeds. My research on blogs discussing the 2010 Haitian earthquake (Figure 3) and on link sharing in Wikipedia and Twitter after the 2011 Japanese tsunami and earthquake as well as research by Irene Eleta on Twitter show instances where information is disseminated across languages and where multilingual users span multiple language groups and act as “bridge nodes” allowing the flow of information between language groups.
Enabling the flow of information between languages has both technical and social dimensions. Machine translation is not without errors, but it still enables engagement with other-language content at a high level and further research and new sources of training data will help to improve machine translation systems continually. In addition, research into the role design plays in helping users discover and diffuse information across languages, including my own research, is needed, and social media companies should use findings from this research and the broader social sciences when building new platforms. Finally, exciting new tools will leverage the skills of both computers and users to cross language frontiers. Duolingo and Monotrans2 are two examples that enable monolingual users to translate content, and, in the case of Doulingo, to also learn a new language at the same time. There will also always be a place for human translation and a role media organisations can play in identifying and verifying information about important events in other languages.
Scott A Hale is a research assistant and doctoral candidate at the Oxford Internet Institute.





















reply report Report comment
Dear Mr. Hale. My name is Victor. T.W. Gustavsson and I go the University of the Hague studying the meaning and use of the English language. After reading your article, I was left with some unanswered question marks. Do computers really translate information in a way that alters the content and meaning of a text from one language to another? And if so, should we leave these translations to computers, if it comes to the point where these faulty translation can cause harm and/or misunderstandings?
Your argument that different countries include different information about the same event is just logical, as different countries have dissimilar cultures and beliefs which will shape what information they focus on and the way they structure their information and websites. For example, Google searches in one language will not give you the same suggestions as if you would Google the same thing in a different language. So it rather comes down to internet censorship which plays a huge role when it comes to what information is allowed to be published on the internet, making these searches bias depending on what country you are searching from or in what language you make the search.
Furthermore, your images showing the different search results of China’s Google and the UK’s Google demonstrate the censorship of China compared to the UK’s freedom of speech. Your argument is based upon the supporting evidence that the search results are different, yet your example actually only proves the opposite as it demonstrates how much influence governments have on the internet. It is only logical that the search results in China will be different than in the UK due to their different cultures and standpoints regarding freedom of speech. If we look at the past, the UK has been much more open as a society and as a government compared to China, therefore, it would only be logical if this were to be represented on the internet.
You are simply stating the obvious. Instead of developing your own ideas or theories, you rephrase what has been addressed in the past by experts in the field. China’s government censors the internet, as the Tiananmen Square example shows; it has done so for years.You mention that “search engines provide one window into the differences in content between languages,” yet I have conducted my own research and have found that searching ‘911’ or ‘Taliban’ on the Arabic Google and the UK Google have similar findings, unlike the Tiananmen Square example. This search was carried out from a computer in The Netherlands, with only a few minutes time difference between each search. I believe your argument is more supporting of government censorship on the internet rather than false translation due to internet translations.
In countries where no government censorship is present, such as Afghanistan or the United Kingdom, the search results are similar because it represents what people post or search on the internet. This suggests that your argument that “search engines try to match query words to the text that appears near images in web pages” is invalid, as it is only due to government censorship.
It therefore should also not be striking that there are differences in results between different countries such as China and the UK, as you suggested. Yet Google, who are determined to encrypt their algorithms due to the recent NSA affair, will prevent China from censoring Google in the future as easily (Washington Post, “Google is encrypting search globally. That’s bad for for the NSA and China’s censor’s”). I am convinced that if we were to compare the results of a Google Images search of “Tiananmen Square” between the Chinese Google and the United Kingdom Google in five year’s time, there would be little difference, as technology is ever improving and censorship is becoming more evident. Therefore I am not sure what your argument states, as your resource contradicts your sophism, actually illustrating that the internet is not free, and that Google’s algorithms can easily be hacked by governments.
You stated that translations on huge encyclopedias such as Wikipedia, are generated by sophisticated computer algorithms which are not nearly as accurate as real-life translators. However, according to Bill Bryson’s Mother Tongue, different languages may have as many as thousands of different words for what we have in English only a few for, “the Arabs are said (a little unbelievably, perhaps) to have 6,000 words for camels and camel equipment”. This could possibly confuse these computer softwares to misinterpret some words which could eventually lead to “overlap” as you said. This raises a question of, just as it is people’s job to translate in real life, should there be designated translators whose job it is to accurately translate content from English to or from any other language. Before the internet existed, works were already being translated and these seem to be much more accurate than many of the articles and pieces on the internet. You can argue that these have been checked over and over again by publishers, but, do computers not double check?
You mentioned explicitly that there are large overlaps between English and other languages with “overlap is between English and Hebrew is 75%”, yet a few sentences later you stated that “several platforms have achieved truly global penetration (Facebook, Twitter, YouTube, and Wikipedia)”. Nonetheless, one big reason why German contains about 16% of the articles in English” is because Wikipedia has a policy where users request pages to be translated. Because English is one of the primary languages in our modern world and most internet websites and activity is done in English, it is only logical to give the English language priority when it comes to translation. Therefore, only the most important (which the user thus decides) gets translated to a foreign language. Country specific topics such as the German National anthem should undoubtedly be different than when it is translated in English.
I do agree howbeit, that machine translations aren’t flawless and that in time these will get more and more sophisticated. But do we really want computers to take over almost everything in the digital world, even the one thing we have developed over the course of thousands of years as a human race, language?
reply report Report comment
Dear Victor,
Thank you for reading and responding to my article. I’m afraid, however, that there have been some misunderstandings. I respond to some questions and point out some of these misunderstandings below.
> Do computers really translate information in a way that alters the content and meaning…
I only mention that machine translation has some errors, and do not discuss machine translation in depth in this piece. The focus of this article is on the content produced by humans in different languages (of which human translations are a small part). In the case of human produced content, yes, there are often differences in meaning and content across languages.
> Your argument that different countries …
This article only discusses languages and not countries. The example Google searches are both performed in the UK on the .com version of Google as stated in the article. Only the languages of the search queries were different. I admit, however, that the example queries could have been better chosen (and originally I had a gallery of many examples, but for technical limitations of this site it was not included. It is available on my own website: http://www.scotthale.net/blog/?p=275).
> “search engines provide one window into the differences in content between languages”
I stand by this, and note that similarity between two languages for one search doesn’t disprove that there are differences between some languages (and data shows most languages). It is also important to note that Google is constantly changing its search algorithms, and it is very possible that they are now using translations of search terms to produce more similar image results in different languages. I know that this was already being considered two years ago when I wrote this article, but I don’t know if it has been implemented.
> In countries where no government censorship is present….
Again, I’m concerned about language, not countries, and
> I am convinced that if we were to compare the results of a Google Images search of “Tiananmen Square” between the Chinese Google and the United Kingdom Google in five year’s time, there would be little difference
I’m not sure on this point. Note again that both of my searches were from the UK and performed on the .com version of Google. If the Chinese government remains successful in ensuring that most mentions of Tiananmen Square in Chinese occur around benign photos (e.g., through controlling the publishing of content in the country with the largest Chinese-speaking population in the world), then any language-independent image search algorithm will most likely find these benign photos and rank them more highly than ‘obscure’ photos that occur around the phrase “Tiananmen Square” in Chinese in a small amount of content.
> You stated that translations on huge encyclopedias such as Wikipedia, are generated by sophisticated computer algorithms which are not nearly as accurate as real-life translators.
I do not state this. In general, Wikipedia does not include raw/pure machine translation without a human in the loop. (https://meta.wikimedia.org/wiki/Machine_translation)
> You mentioned explicitly that there are large overlaps between English and other languages with “overlap is between English and Hebrew is 75%”, yet a few sentences later you stated that “several platforms have achieved truly global penetration (Facebook, Twitter, YouTube, and Wikipedia)”.
There is no contradiction between these two sentences. The first discusses content overlap between languages; the second discusses the geographic breadth of users of websites.
> I do agree howbeit, that machine translations aren’t flawless and that in time these will get more and more sophisticated. But do we really want computers to take over almost everything in the digital world, even the one thing we have developed over the course of thousands of years as a human race, language?
On this point we can agree :-). Humans play important roles in producing, seeking, and consuming content in different languages. My research argues that a better understanding these human roles (particularly those of bilinguals) is needed in order to better design platforms. I encourage you to take a look at my own website and get in contact with the contact form there if you want to discuss anything further. http://www.scotthale.net/
Best wishes,
Scott